Snowflake Summit 2026: What the Agentic Enterprise Actually Means for Your Data Team
Snowflake shipped 26+ launches in four days. Underneath the announcements is one architectural bet — Snowflake wants to be the control plane for the agentic enterprise. Here is the signal cut from the noise, and what it changes for the teams we work with.
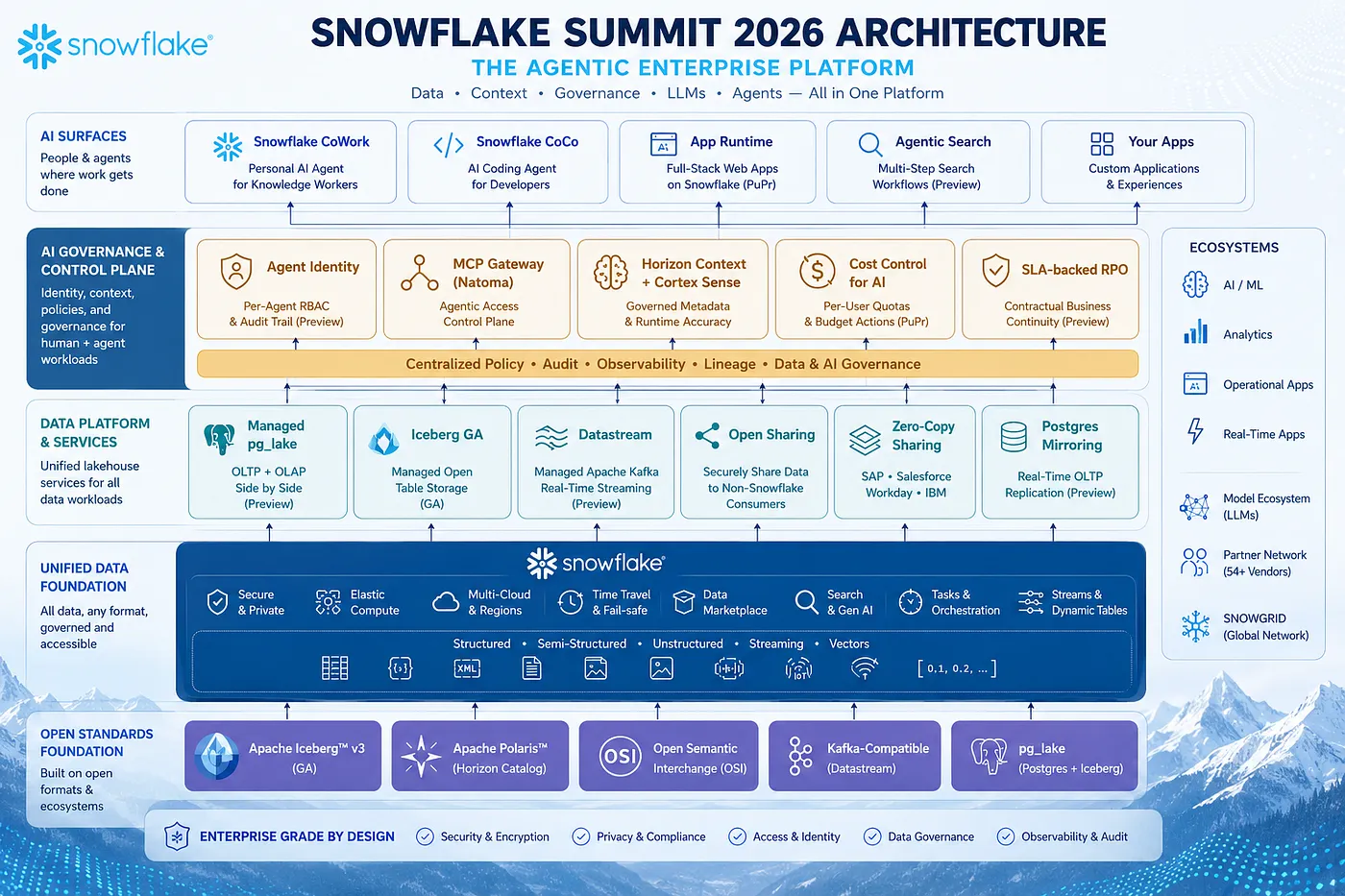
Architecture diagram via Luke Turanski (Medium)
Snowflake Summit 2026 wrapped up at Moscone Center on June 4th — 20,000+ attendees, a keynote co-hosted with Anthropic President Daniela Amodei, a $6B AWS commitment, and 26+ product launches. I spend most of my year inside Snowflake accounts for the companies we work with, so I read these announcements through one filter: what actually changes the work on Monday morning. This is that cut — the themes that matter, the launches worth your attention, and what to do about them.
If 2024 was “Snowflake plus AI,” and 2025 was “AI inside Snowflake,” then 2026 is unambiguously “Snowflake is the agentic enterprise platform.” CEO Sridhar Ramaswamy framed the whole thing in one line: “The model is not your unique advantage. It’s when you combine models with your data that things begin to shine.” Everything announced this week is downstream of that idea.
Six themes that ran through everything
Strip away the product names and Summit 2026 was making six bets. If you only remember the launches, you will chase features. If you remember the bets, you will know which features to actually adopt.
- Snowflake wants to be the control plane. CoWork and CoCo are the user-facing layer of a platform where your data, governance, security, context, and the LLMs all live in the same place. The co-location is the point — when the model, the data, the policies, and the business context all run together, you stop stitching systems and start building.
- Context belongs where the data lives. Cortex Sense and Horizon Context argue your semantic layer should not be a separate system you maintain — it should sit with the data it describes. Fragmented context is the root cause of most “the AI got it wrong” moments.
- Open is the strategy, not the concession. Apache Iceberg v3 GA, a 54-vendor open semantic standard, a Polaris-powered Horizon Catalog, and open table-format sharing all signal Snowflake treating openness as a weapon rather than a liability.
- Postgres is now a first-class citizen. pg_lake, Postgres Data Mirroring, and Managed Postgres make Snowflake a serious answer for teams that live in OLTP and want lakehouse benefits without a migration. OLTP and OLAP on one platform, under one governance model, is a real shift.
- Streaming is table stakes. Datastream removes the Kafka-management tax and pulls real-time data into the same governance envelope as everything else.
- Agents need identity. The Natoma acquisition and Agent Identity make the same point — the era of agents running as anonymous processes is over. Governed agentic access is the new zero-trust, and Snowflake’s audit surface now covers every autonomous agent, not just human users.
AI & developer experience: CoCo, CoWork, and Cortex
CoCo Desktop is GA. Cortex Code got a rename and a real product — Snowflake CoCo is now a native desktop app with extensions for VS Code, Claude Code, and even Excel. It is Snowflake’s fastest-growing offering (7,100+ users), and GA finally gets it out of the browser and into the workflow. If you build anything on Snowflake, this is the new default starting point.
CoWork is the personal work agent (formerly Snowflake Intelligence, now GA). It runs natural-language queries against your enterprise data, does multi-step reasoning, executes actions, and ships a Skill Catalog for reusable agent workflows — powered by Claude, grounded in your Snowflake perimeter. User Memory (preview) layers personalization on top: it learns what “revenue” means to you, not just to the data model. NextGen Artifacts make CoWork outputs shareable and certifiable, so an AI-generated dashboard can carry a trust stamp from someone with the right role.
Cortex AI Function Studio and Custom AI Functions (public preview) are the piece I am most interested in for client work. You describe a task in natural language and the Studio automates prompt engineering, model selection, and benchmarking against your actual data — text, documents, images, audio, video. Then you wrap that domain logic — compliance checks, extraction schemas, entity classification — into callable SQL functions any query or pipeline can invoke. Building custom AI functions used to be duct tape and prayer; now it is a guided product.
Two more worth noting: Agentic Search turns Cortex Search from point-in-time retrieval into iterative, multi-step research where an agent refines queries and synthesizes across results, and the Snowsight Pipeline Builder gives analysts a visual, no-code way to build pipelines on top of tasks and dynamic tables. And Grok (xAI) joins the Cortex model roster alongside Claude, GPT, Gemini, Llama, Mistral, and DeepSeek — more model choice inside the same governed boundary.
AI governance: the part most teams will under-rate
This is the category I would push every data leader to read closely, because it is the difference between a fun demo and something you can put in production.
Agent Identity (preview) is the security primitive the agentic enterprise has been waiting for. Traditional IAM was built for humans. Agent Identity gives every AI agent a cryptographic, verifiable identity before it touches a Snowflake resource — with per-agent RBAC (not inherited from whoever launched it), dynamic masking by agent type, and a full audit trail. As EVP Christian Kleinerman put it: “Traditional security models were designed for human users, not autonomous software agents.”
The Natoma acquisition extends that perimeter past your data to your tools. Natoma is an enterprise MCP (Model Context Protocol) gateway — centralized identity, access policy, and audit at the tool-call level, governing exactly what an agent can do against external APIs and SaaS systems. The strategic read: Snowflake is becoming the control plane for agentic access, not just agentic data.
And Cortex Sense + Horizon Context are two halves of the same context story. Horizon Context is the collection-and-enrichment layer inside Horizon Catalog — it ingests external metadata (Wave 1: PostgreSQL, SQL Server, Tableau, Power BI, dbt), stitches column-level lineage, auto-generates docs, and exposes it all through hybrid semantic + keyword search. Cortex Sense is the runtime half: it assembles those definitions, policies, and domain knowledge dynamically and injects them into every agent query. Snowflake’s headline number — 86% accuracy on structured enterprise questions versus 24% with generic frontier models — is what you get when the catalog and the runtime finally speak the same language.
The accuracy gap between “LLM on a raw warehouse” and “LLM on a governed semantic layer” is the entire ballgame. Everything Snowflake shipped in governance this year is in service of closing it.
Rounding out governance: Cost Control for AI (public preview) brings per-user Cortex quotas, budget-triggered actions (pause, alert, reroute), and function-level spend visibility — you can finally budget AI workloads the way you budget a warehouse. And SLA-backed RPO turns recovery-point objectives into a contractual commitment, the kind of thing that unlocks budgets in banking, healthcare, and government.
Data engineering & collaboration: Postgres grows up, streaming gets cheap
The Postgres story is the sleeper of the show. Managed pg_lake gives a Postgres instance zero-ETL read/write access to Iceberg tables in Snowflake-managed storage — your OLTP app queries lakehouse-scale data through native SQL, against a single live governed copy. Postgres Data Mirroring continuously replicates Postgres changes into the Snowflake lakehouse in real time, so operational and analytical views stay in sync with no pipeline in between. Together with Managed Postgres, this is the “Postgres and Snowflake, not Postgres vs. Snowflake” moment.
Snowflake Datastream (preview) is a fully managed, Kafka-compatible streaming service — a drop-in replacement for existing Kafka topologies with no code changes. The architecture is clever: stateless processors write directly to blob storage, so a topic in Datastream is a table in Snowflake, with sub-second latency, no broker fleet to babysit, and automatic governance inheritance. The data-engineering tax on real-time workloads just dropped sharply.
On the openness front, Manage Storage for Iceberg is GA — Snowflake owns compaction, manifest management, and cleanup while you keep the ability to read those same tables from Spark, Trino, or any Iceberg engine. That is the “open but managed” promise actually delivered. And a cluster of sharing capabilities — Open Sharing to non-Snowflake consumers, Zero-Copy Sharing with SAP / Salesforce / Workday / IBM, Sharing Data to Agents, Resharing, Multi-Party Collaboration, and Heterogeneous Data Access via Polaris — all push toward one query layer over any data, anywhere, with governance applied consistently.
The old way vs. the agentic-enterprise way
Strip the announcements down to the practical before-and-after, and the shape of the bet gets clear. This is the shift Summit 2026 is really selling — not a feature list, but a different default for how AI, data, and governance fit together.
| Capability | Before Summit 2026 (DIY / pre-agentic) | With Snowflake Summit 2026 |
|---|---|---|
| Accuracy on enterprise questions | Generic LLM pointed at raw tables — ~24%, confidently wrong | Cortex Sense + Horizon Context grounding — ~86% |
| Business context / semantic layer | A separate system you hand-maintain; drifts from the data | Lives with the data in Horizon Context, injected at runtime |
| Agent security | Agents run anonymously, inheriting the launching user’s access | Agent Identity — per-agent RBAC, masking, full audit trail |
| Streaming ingestion | Self-managed Kafka clusters and the ops tax that follows | Datastream — managed, Kafka-compatible; a topic is a table |
| OLTP + analytics | Separate Postgres and warehouse with an ETL pipeline between | pg_lake + Postgres Mirroring — one governed copy, no pipeline |
| Data sharing reach | Both provider and consumer must live inside Snowflake | Open Sharing to non-Snowflake consumers via open table formats |
| AI spend control | Surprise Cortex bills, no per-user guardrails | Per-user quotas + budget-triggered actions, function-level visibility |
What this actually changes for your team
| If you are… | The launch that matters | What to do about it |
|---|---|---|
| Building “AI on our data” and seeing it hallucinate | Cortex Sense + Horizon Context | Stop trying to fix the model. Invest in the semantic/context layer — that is where 24% becomes 86%. |
| Running agents against production data | Agent Identity + Natoma MCP Gateway | Treat agents as identities with their own RBAC and audit trail before you scale them, not after. |
| Paying a Kafka or streaming-ops tax | Datastream | Pilot it as a drop-in for one topic. Sub-second latency with no broker fleet is a real cost line removed. |
| Living in Postgres, wanting lakehouse analytics | pg_lake + Postgres Data Mirroring | You may not need the migration you were dreading. Evaluate the “Postgres and Snowflake” path first. |
| Worried about a surprise Cortex bill | Cost Control for AI | Set per-user quotas and budget actions on day one. Govern AI spend like warehouse spend. |
A note on release stages, because it matters for planning: a lot of this is Preview or Public Preview, not GA. CoCo Desktop, CoWork, Grok in Cortex, and Manage Storage for Iceberg are GA. Cortex AI Function Studio, App Runtime, Multi-Party Collaboration, and Cost Control are Public Preview. Agent Identity, Cortex Sense, Datastream, pg_lake, and most of the sharing features are Preview — available for evaluation, not recommended for production without review. Snowflake’s Preview Features page is the authoritative source; check it before you build a roadmap on any single item.

Want a Summit 2026 readout tailored to your Snowflake account?
We run a focused session that maps these launches to your actual architecture — what to pilot now, what to wait on, and where Agent Identity, Cortex Sense, and Datastream would move the needle for you specifically. No slideware, just a working plan.
Where I would start
Do not try to adopt 26 features. Pick the one bet that maps to your biggest current pain. For most of the teams we work with, that is context and governance — the gap between an AI demo and something an executive trusts. Start there: get your dbt models and metric definitions healthy, wire Horizon Context to your existing metadata, and only then put Cortex (or a CoWork agent) in front of it. Governance first, semantic layer second, conversational analytics third. Skip the order, skip the value.
Summit 2026 was less a conference and more an architectural declaration: the agentic enterprise is no longer coming, it is here. A lot shipped, more is coming, and the documentation is still landing. But the through-line is clear — the advantage is not the model, it is the model standing on top of your governed data. That has been the thesis of our work for years. It is good to see the platform catch up to it.
Frequently Asked Questions
Is Snowflake CoWork the same thing as Snowflake Intelligence?
Yes — CoWork is the rebrand of Snowflake Intelligence, and it went GA at Summit 2026. It is positioned as the personal AI agent for knowledge workers: natural-language queries against enterprise data, multi-step reasoning, action execution, and a Skill Catalog of reusable workflows, powered by Claude and grounded in your Snowflake data perimeter. The rename signals intent — it is meant to be an assistant that anticipates, not just a chatbot you prompt.
What is Agent Identity and why does it matter?
Agent Identity (in preview) gives every AI agent its own cryptographic, verifiable identity before it can access any Snowflake resource. Crucially, an agent gets its own RBAC rather than inheriting permissions from the human who launched it, plus dynamic masking by agent type and a complete audit trail. It matters because traditional IAM was built for humans — once you have autonomous agents reading and writing production data, you need a security model designed for software, and this is Snowflake’s answer.
Does pg_lake mean I can avoid a Postgres-to-Snowflake migration?
Often, yes — that is the whole pitch. Managed pg_lake gives a Snowflake Postgres instance zero-ETL read/write access to Apache Iceberg tables in Snowflake-managed storage, and Postgres Data Mirroring continuously replicates Postgres changes into the lakehouse in real time. Together they let OLTP and analytical workloads share one governed copy of the data, which means many teams can get lakehouse benefits without ripping out their transactional layer. Evaluate that path before committing to a migration.
How much of what was announced is actually production-ready?
A meaningful chunk is still Preview or Public Preview, not GA. GA items include CoCo Desktop, CoWork, Grok in Cortex AI, and Snowflake-managed storage for Iceberg. Public Preview includes Cortex AI Function Studio, App Runtime, Multi-Party Collaboration, and Cost Control for AI. Agent Identity, Cortex Sense, Datastream, pg_lake, and most sharing features are Preview — fine for evaluation, but not recommended for production without review. Always confirm current status on Snowflake’s Preview Features page before planning a rollout.
What is the single most important takeaway for a data leader?
That the advantage is not the model — it is the model combined with your governed data and context. The 86%-versus-24% accuracy gap Snowflake highlighted between Cortex Sense and generic frontier models is the entire case for investing in your semantic layer, catalog, and governance before you invest in fancier AI. Get the context layer right and the AI gets dramatically more accurate almost for free. Skip it and you have a confident demo that occasionally lies to your CFO.
Need help building your data platform?
At CData Consulting, we design, build, and operate modern data infrastructure for companies across North America. Whether you are planning a migration, optimizing costs, or building from scratch — let's talk.
Get data engineering insights delivered to your inbox
Join our newsletter for weekly insights on Snowflake, data architecture, and modern analytics.